
I, Tìm hiểu chung về Sharding
1, Sharding là gì, tại sao phải sharding.
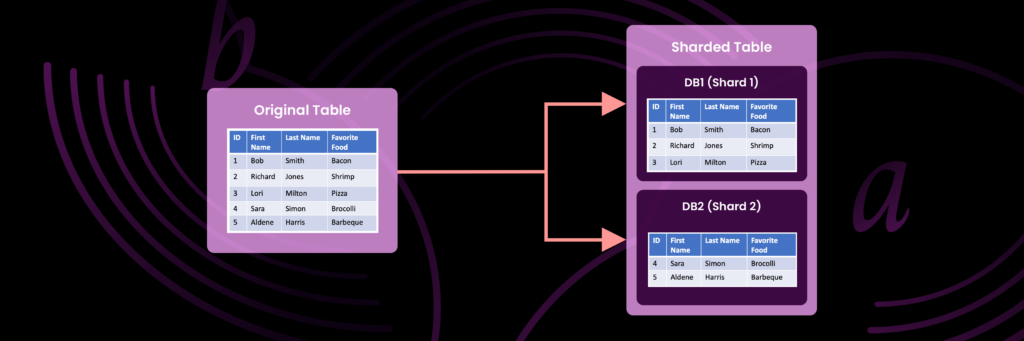
Database sharding là chiến lược xử lý cấu trúc dữ liệu giúp tăng hiệu suất cơ sở dữ liệu bằng cách chia dữ liệu thành các khối rồi phân bổ các khối này một cách “thông minh” trên nhiều bảng, nhiều instances hoặc nhiều máy chủ cơ sở dữ liệu. Những khối dữ liệu này được gọi là phân đoạn (shard), trong khi mỗi shard chứa một tập hợp con dữ liệu của chúng. Tất cả các shard đại diện cho toàn bộ tập hợp dữ liệu và mỗi hàng dữ liệu chỉ tồn tại trong một shard.
Sharding cho phép cơ sở dữ liệu xử lý nhiều giao dịch hơn và lưu trữ nhiều dữ liệu hơn vì công việc được thực hiện bởi nhiều máy hơn. Sharding cơ sở dữ liệu rất hiệu quả đối với các môi trường phân tán, quy mô lớn đòi hỏi khả năng mở rộng. Sharding cơ sở dữ liệu là một ví dụ về kiến trúc không chia sẻ (share nothing). Các shard là các máy chủ cơ sở dữ liệu độc lập; một shard không chia sẻ bất kỳ tài nguyên máy tính nào với các shard khác.
Hãy nhớ: mỗi shard đại diện cho một tập hợp con dữ liệu của cơ sở dữ liệu và tất cả các shard đại diện cho toàn bộ tập hợp dữ liệu.
2, Sharding khác gì Partitioning?
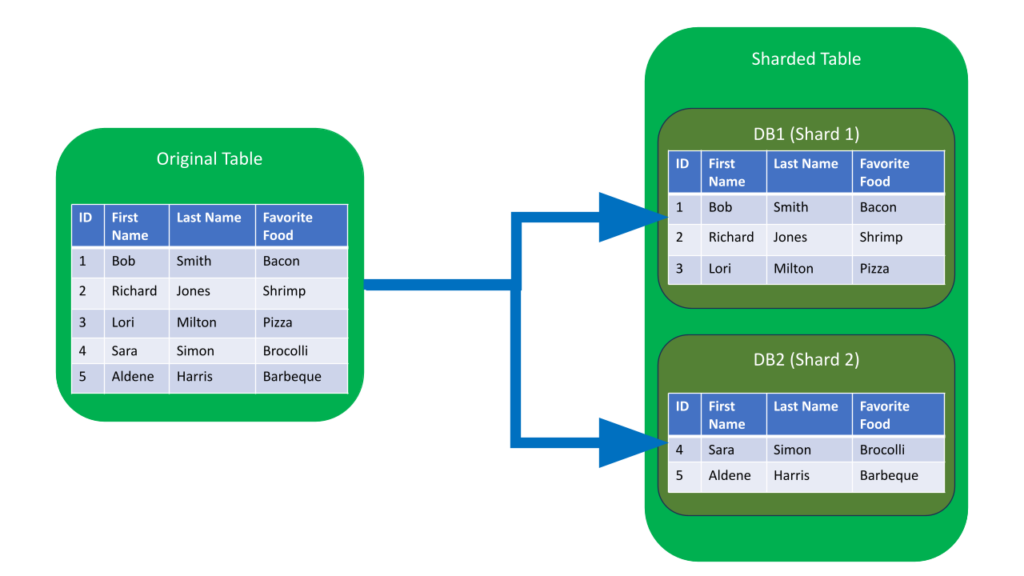
Bây giờ chúng ta đã hiểu rằng sharding cơ sở dữ liệu là sự phân phối chiến lược các khối dữ liệu trên nhiều máy chủ cơ sở dữ liệu, hãy so sánh nó với phân vùng dữ liệu (partitioning) (trên một máy). Partitioning tương tự như sharding ở chỗ nó liên quan đến việc phân chia dữ liệu cơ sở dữ liệu dựa trên một loại khóa nào đó. Tuy nhiên, sự khác biệt chính nằm ở phạm vi và cách bạn phân chia dữ liệu.
Trong Partitioning, sự phân chia xảy ra trong một máy chủ cơ sở dữ liệu. Dữ liệu được chia thành các phân đoạn (segments), được gọi là phân vùng (partitions), nhưng vẫn nằm trong một hệ thống cơ sở dữ liệu. Nó giống như việc tổ chức các phần khác nhau trong một kho duy nhất thay vì phân chia, giúp phân tán hàng hóa ra nhiều kho (Sharding). Mỗi partitions, giống như một shard, chứa một tập hợp con của toàn bộ tập dữ liệu, nhưng không giống như partitions, tất cả chúng đều nằm trong cùng một máy chủ cơ sở dữ liệu. Cách tiếp cận này đặc biệt có lợi cho việc quản lý các bảng lớn và có thể cải thiện hiệu suất truy vấn mà không cần phân phối tải trên nhiều máy chủ.
3, Khi nào chúng ta nên Shard Database?
Chúng ta nên shard DB khi:
- Lưu lượng truy cập cao và khối lượng dữ liệu lớn: Nếu cơ sở dữ liệu của bạn đang gặp khó khăn dưới tải của hàng triệu người dùng hoặc hàng terabyte dữ liệu, đã đến lúc cân nhắc việc bảo vệ cơ sở dữ liệu của bạn.
- Nhu cầu về khả năng mở rộng: Khi doanh nghiệp của bạn mở rộng quy mô nhanh chóng, bạn thấy trước sự tăng trưởng liên tục về dữ liệu và cơ sở người dùng.
- Suy giảm hiệu suất: Nếu bạn nhận thấy phản hồi truy vấn chậm hơn và phân tích của bạn cho thấy nút thắt cổ chai ở cấp cơ sở dữ liệu.
Không nên shard khi
- Kích thước cơ sở dữ liệu nhỏ đến trung bình: Dành cho cơ sở dữ liệu chưa đạt đến giới hạn trên về khả năng lưu trữ hoặc xử lý.
- Khối lượng công việc đơn giản: Nếu cơ sở dữ liệu của bạn không gặp phải các truy vấn phức tạp hoặc tỷ lệ giao dịch cao.
- Nguồn lực kỹ thuật hạn chế: Sharding đòi hỏi chuyên môn cao để triển khai và quản lý. Nếu nhóm của bạn chưa sẵn sàng cho sự phức tạp đó, hãy tạm dừng (hoặc tìm kiếm một giải pháp đơn giản hơn).
4, Các kiên trúc Sharding
Key-Based Database Sharding
Sharding dựa trên khóa sử dụng một giá trị cụ thể, như ID người dùng hoặc thời gian, làm khóa.
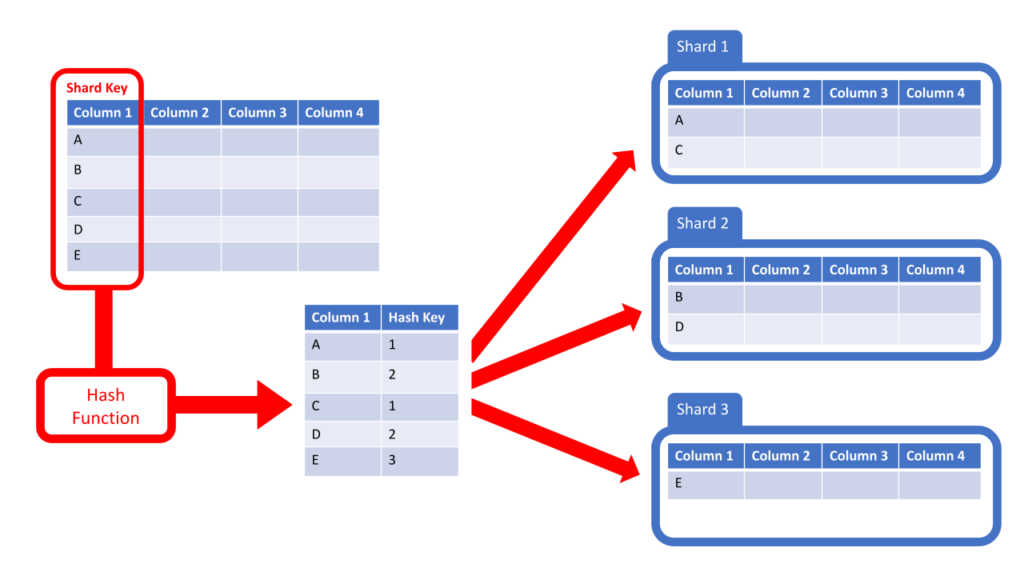
Theo cách tiếp cận này, chúng ta phải chọn một khóa để xác định shard nào của hàng dữ liệu sẽ tồn tại. Trong sơ đồ của chúng tôi, chúng tôi đã chọn Cột 1 cho khóa phân đoạn. Sau đó, chúng tôi áp dụng hàm băm cho mục dữ liệu của mình. Khóa băm xác định phân đoạn dữ liệu của chúng tôi sẽ chuyển đến.
Range-Based Database Sharding (i.e., Horizontal Sharding)
Với Range-Based Sharding , dữ liệu được phân chia dựa trên một phạm vi giá trị, chẳng hạn như phạm vi ngày hoặc vị trí địa lý.

Trong sơ đồ, chúng tôi đã chọn phân đoạn dựa trên cột Màu sơn. Màu sơn là một mã số. Cơ sở dữ liệu sẽ lấy mã này và sử dụng phạm vi của phân đoạn để xác định vị trí đặt dữ liệu.
Vertical Database Sharding
Vertical Sharding phân chia dữ liệu dựa trên các cột trong bảng và phân phối các cột khác nhau trên nhiều shard khác nhau. Mẫu này được sử dụng để chia các bảng rộng thành nhiều bảng. Một bảng sẽ hẹp hơn bảng kia. Bảng hẹp này sẽ chứa dữ liệu được truy vấn phổ biến nhất. Trong những trường hợp hiếm hoi khi bạn cần dữ liệu từ bảng thứ hai, bạn có thể join bảng thứ hai với bảng đầu tiên.

Vertical Sharding phù hợp với các bảng có cột lớn, không được sử dụng, nâng cao hiệu suất bằng cách cách ly dữ liệu được truy cập thường xuyên. Chiến lược này hữu ích trong môi trường triển khai phân tích. Khối lượng công việc phân tích thường cần truy cập vào các bảng rất rộng. Tuy nhiên, nó có thể làm phức tạp các truy vấn cần truy cập nhiều phân đoạn cùng một lúc.
Directory-Based Database Sharding
Directory-Based Sharding Phân đoạn dựa trên thư mục phân chia dữ liệu dựa trên các cột trong bảng và phân phối các cột khác nhau trên nhiều phân đoạn khác nhau.
Trong sơ đồ bên dưới, chúng ta xem lại cột Màu sơn mà chúng ta đã sử dụng trước đó. Trong ví dụ này, chúng tôi đang sử dụng Directory-Based Sharding (từ điển – còn được gọi là bảng tra cứu) để đặt dữ liệu vào một phân đoạn cụ thể.
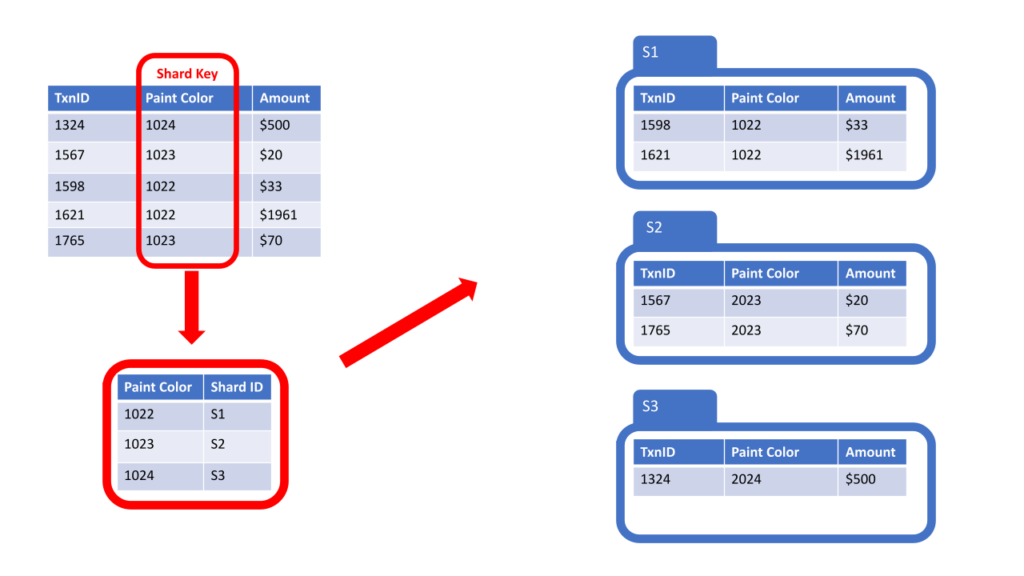
Directory-Based Sharding phù hợp với các bảng có cột lớn, không được sử dụng, nâng cao hiệu suất bằng cách cách ly dữ liệu được truy cập thường xuyên.
Phương pháp Directory-Based Sharding này bao gồm một thư mục tra cứu để theo dõi dữ liệu nào nằm trên phân đoạn nào. Mặc dù nó mang lại sự linh hoạt cao và có thể xử lý tốt các bản phân phối không đồng đều, nhưng nó có nguy cơ khiến thư mục tra cứu trở thành một điểm lỗi đơn. Việc bảo trì và tính nhất quán của thư mục cũng là những cân nhắc quan trọng.
5, Sharding thủ công và Sharding tự động
Chúng ta đã thảo luận về các chiến lược sharding nhưng vẫn chưa thảo luận chi tiết quan trọng nhất: Ai sẽ xử lý sharding? Hãy nói theo cách khác. Bạn có thể phân chia cơ sở dữ liệu theo cách thủ công hoặc bạn có thể sử dụng lớp phần mềm trung gian (middleware) hoặc cơ sở dữ liệu được thiết kế để tự động phân chia dữ liệu một cách hiệu quả.
Chúng ta hãy xem các phương pháp cụ thể mà chúng ta có thể sử dụng để triển khai cơ sở dữ liệu được phân chia thủ công hoặc tự động:
Tự động Sharding: Sử dụng cơ sở dữ liệu SQL phân tán
Cơ sở dữ liệu SQL phân tán vốn hỗ trợ phân chia tự động và đơn giản hóa khả năng mở rộng cũng như bảo trì.
Ưu điểm: Built-in sharding, khả năng mở rộng, tính sẵn sàng cao và giảm bảo trì. Được thiết kế từ đầu để tự động phân chia dữ liệu của bạn.
Nhược điểm: Có thể yêu cầu di chuyển từ các hệ thống hiện có và chuyên môn vận hành mới. Công bằng mà nói, tất cả các giải pháp sharding đều yêu cầu thay đổi môi trường và học các kỹ năng mới. Sử dụng cơ sở dữ liệu được thiết kế để tự động phân chia là giải pháp lâu dài tốt nhất.
Tự động Sharding: Giải pháp sử dụng phần mềm trung gian middleware
Sử dụng phần mềm trung gian như ProxySQL hoặc Vitess cho cơ sở dữ liệu MySQL. Những công cụ này nằm giữa ứng dụng và cơ sở dữ liệu của bạn, xử lý logic phân chia một cách minh bạch.
Ưu điểm: Đơn giản hóa quy trình phân chia và minh bạch đối với ứng dụng.
Nhược điểm: Thêm một lớp, phần mềm cần quản lý. Điều này có thể làm tăng chi phí phần mềm, phần cứng và quản trị.
Sharding thủ công hoặc tự động: Sử dụng cơ sở dữ liệu có khả năng phân chia tích hợp
Các cơ sở dữ liệu như MySQL Cluster hoặc MariaDB bao gồm các khả năng phân chia tích hợp sẵn để có giải pháp phân chia dựa trên MySQL hơn.
Ưu điểm: Tích hợp tự nhiên với hệ sinh thái MySQL.
Nhược điểm: Có thể kém linh hoạt hơn so với các cơ sở dữ liệu SQL phân tán khác vì khả năng phân chia đã được thêm vào sau. Ngay từ đầu, cơ sở dữ liệu SQL phân tán đã được thiết kế để hỗ trợ tự động phân chia.
Sharding thủ công: Sharding lớp ứng dụng
Sửa đổi logic của ứng dụng của bạn để phân phối dữ liệu trên nhiều phiên bản cơ sở dữ liệu. Cách tiếp cận này mang lại cho bạn quyền kiểm soát nhưng đòi hỏi công việc phát triển đáng kể.
Ưu điểm: Kiểm soát cao đối với logic sharding.
Nhược điểm: Đòi hỏi nỗ lực phát triển và bảo trì đáng kể. Việc mở rộng quy mô đòi hỏi phải lập kế hoạch rất nhiều và việc thực hiện thường đòi hỏi thời gian ngừng hoạt động. Việc thực hiện phương pháp này sẽ dẫn đến một dự án tư vấn sẽ lặp lại trong suốt vòng đời của ứng dụng. Ôi!
Tóm lại, việc phân chia cơ sở dữ liệu có thể tốn rất nhiều công sức. Dưới đây là một cái nhìn tổng quan sơ bộ, ở cấp độ rất cao về loại dự án này trông như thế nào trong thực tế.
6, Các bước dự án phân chia cơ sở dữ liệu
1, Xác định nhu cầu phân chia: Đánh giá cơ sở dữ liệu của bạn để hiểu nhu cầu phân chia. Xem xét các yếu tố như khối lượng dữ liệu, tỷ lệ giao dịch và các vấn đề về hiệu suất.
2, Xác định nhu cầu tính toán và lưu trữ: Đây là một trong những bước quan trọng nhất trong quy trình này. Bạn có thể cần mua phần cứng nếu bạn đang bảo vệ cơ sở dữ liệu tại chỗ. Bước này là nơi bạn chọn phần cứng của mình. Nếu bạn đang chạy trong môi trường đám mây thì đây là nơi bạn cố gắng ước tính chi phí của các máy ảo và bộ nhớ cần thiết. Và đừng quên phần mềm. Bạn có thể cần giấy phép hoặc sản phẩm bổ sung. Nếu bạn đang sử dụng phần mềm nguồn mở (di chuyển thông minh), bạn có thể cần phải tăng thỏa thuận hỗ trợ của mình.
3, Tạo môi trường thử nghiệm: Môi trường thử nghiệm giúp đơn giản hóa quy trình trong nhiều tình huống. Mặc dù đau đớn nhưng việc làm xáo trộn môi trường thử nghiệm không tệ bằng việc phá hủy hệ thống sản xuất. Đừng quên quay lại tài liệu định cỡ của bạn để thêm môi trường thử nghiệm.
4, Nhận tài nguyên điện toán và lưu trữ: Đừng quên đặt mua phần cứng và cấp phép cho phần mềm cần thiết.
5, Chọn chiến lược phân mảnh: Quyết định giữa phân mảnh dựa trên khóa, dựa trên phạm vi, dọc hoặc dựa trên thư mục. Lựa chọn của bạn phải phù hợp với cấu trúc dữ liệu và kiểu sử dụng của bạn.
6, Chọn khóa phân đoạn: Khóa này xác định cách phân phối dữ liệu trên các phân đoạn. Chọn một khóa đảm bảo phân phối dữ liệu cân bằng và giảm thiểu các truy vấn chéo phức tạp.
7, Triển khai logic phân mảnh: Điều này có thể được thực hiện ở cấp ứng dụng. Thêm lớp phân mảnh phía trên máy chủ cơ sở dữ liệu hoặc sử dụng hệ thống quản lý cơ sở dữ liệu hỗ trợ phân mảnh tự động.
8, Kiểm tra kỹ lưỡng: Kiểm tra nghiêm ngặt cơ sở dữ liệu được phân chia trước khi đi vào hoạt động để đảm bảo tính toàn vẹn và hiệu suất của dữ liệu.
9, Giám sát và điều chỉnh: Sau khi triển khai, liên tục giám sát hiệu suất của cơ sở dữ liệu được phân chia và cân bằng lại các phân đoạn nếu cần.
II, Sharding cơ sở dữ liệu với phần mềm ProxySQL
1, Mô hình triển khai
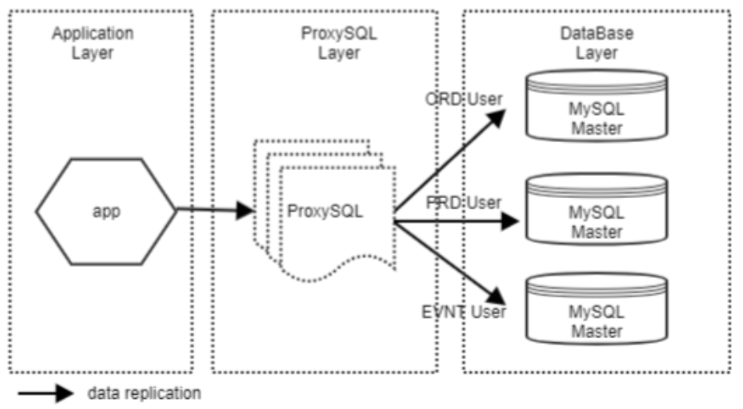
Proxy server: ssh chi@10.198.68.115
DB server 1: ssh chi@10.1.1.21
sudo hostnamectl set-hostname db01
DB server 2: ssh chi@10.1.1.22
sudo hostnamectl set-hostname db02
DB server 3: ssh chi@10.1.1.23
sudo hostnamectl set-hostname db03
2, Các bước cài đặt
Cài đặt 03 DB MySQL server:
sudo apt update
sudo apt install net-tools telnet
sudo apt install mysql-server
sudo systemctl start mysql.service
nano /etc/mysql/mysql.conf.d/mysqld.cnf
change listen port, address
sudo mysql
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
exit
sudo mysql_secure_installation
mysql -u root -p
CREATE USER 'app'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON . TO 'app'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
exit
systemctl status mysql.serviceCài đặt ProxySQL
wget https://github.com/sysown/proxysql/releases/download/v2.6.2/proxysql_2.6.2-ubuntu22_amd64.deb
sudo apt install ./proxysql_2.6.2-ubuntu22_amd64.deb
systemctl enable proxysql
systemctl start proxysql
mysql -u admin -padmin -h 127.0.0.1 -P6032 --prompt='ProxySQL> '
Mặc định tài khoản admin của ProxySQL sẽ có mật khẩu mặt định là admin luôn, vì vậy ta nên tiến hành đổi lại mật khẩu.
UPDATE global_variables SET variable_value='admin:adminPassW0rd' WHERE variable_name='admin-admin_credentials';
LOAD ADMIN VARIABLES TO RUNTIME;
SAVE ADMIN VARIABLES TO DISK;Tiếp theo ta sẽ tiến hành cấu hình thêm các VPS MySQL đã được tạo từ trước:
INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (1,'10.1.1.21',3306);
INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (1,'10.1.1.22',3306);
INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (1,'10.1.1.23',3306);
SELECT hostgroup_id,hostname,port,status FROM mysql_servers;Chạy trên các MySQL
CREATE USER 'monitor'@'%' IDENTIFIED BY 'monitorPass';
GRANT SELECT ON sys.* TO 'monitor'@'%';
FLUSH PRIVILEGES;CREATE USER 'app'@'%' IDENTIFIED BY 'password';
GRANT ALL ON *.* TO 'app'@'%';
FLUSH PRIVILEGES;Chạy trên Admin ProxySQL
UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_username';
UPDATE global_variables SET variable_value='monitorPass' WHERE variable_name='mysql-monitor_password';
UPDATE global_variables SET variable_value='2000' WHERE variable_name IN ('mysql-monitor_connect_interval','mysql-monitor_ping_interval','mysql-monitor_read_only_interval');
LOAD MYSQL VARIABLES TO RUNTIME;
SAVE MYSQL VARIABLES TO DISK;
LOAD MYSQL SERVERS TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
SELECT * FROM monitor.mysql_server_connect_log ORDER BY time_start_us DESC LIMIT 10;Sau khi tạo xong, ta sẽ thêm User vừa tạo vào ProxySQL.
mysql -u admin -padminPassW0rd -h 127.0.0.1 -P6032 --prompt='ProxySQL> '
INSERT INTO mysql_users(username,password,default_hostgroup) VALUES ('app','password',1);
LOAD MYSQL USERS TO RUNTIME;
SAVE MYSQL USERS TO DISK;
SELECT hostgroup_id,hostname,port,status FROM mysql_servers;Kết nối bằng User ứng dụng vào Client ProxySQL
mysql -u app -p -h 127.0.0.1 -P 6033 --prompt='ProxySQLClient> '
select @@hostname;
show databases;Chạy trên các MySQL
create database edu_test;
use edu_test;
drop TABLE truong ;
CREATE TABLE truong (id int NOT NULL AUTO_INCREMENT PRIMARY KEY, matinh int, tentruong VARCHAR(256),ghichu VARCHAR(265) );Chạy trên Admin ProxySQL
INSERT INTO mysql_query_rules (rule_id, active, match_pattern, destination_hostgroup, apply) VALUES
(1, 1, 'INSERT INTO truong (matinh,tentruong) values (1,', 1, 1),
(2, 1, 'INSERT INTO truong (matinh,tentruong) values (2,', 2, 1),
(3, 1, 'INSERT INTO truong (matinh,tentruong) values (3,', 3, 1);
INSERT INTO mysql_query_rules (active, match_digest, destination_hostgroup, apply)
VALUES (1, '^SELECT .* truong', 2, 1);
INSERT INTO mysql_query_rules (active, match_digest, match_pattern, destination_hostgroup, apply) VALUES
(1, '^SELECT .* truong','matinh= 1', 1, 1),
(1, '^SELECT .* truong','matinh= 2', 2, 1),
(1, '^SELECT .* truong','matinh= 3', 3, 1);
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;Chạy trên Client ProxySQL
INSERT INTO truong (matinh,tentruong) values (1,'Cụm 1 Truong 1');
INSERT INTO truong (matinh,tentruong) values (1,'Cụm 1 Truong 2');
INSERT INTO truong (matinh,tentruong) values (2,'Cụm 2 Truong 1');
INSERT INTO truong (matinh,tentruong) values (2,'Cụm 2 Truong 2');
INSERT INTO truong (matinh,tentruong) values (3,'Cụm 3 Truong 1');Chạy trên Admin ProxySQL
SELECT hostgroup,count_star,schemaname,sum_time, digest_text from stats_mysql_query_digest ORDER BY digest;
SELECT rule_id,username, match_digest, match_pattern, destination_hostgroup from mysql_query_rules where apply=1;
SELECT * FROM stats.stats_mysql_connection_pool;
SELECT * FROM stats_mysql_commands_counters WHERE Total_cnt;
SELECT hostgroup,digest,digest_text,count_star, sum_rows_affected FROM stats_mysql_query_digest ORDER BY sum_time DESC;
SELECT hostgroup hg, sum_time, count_star, digest_text FROM stats_mysql_query_digest ORDER BY sum_time DESC;
SELECT hostgroup hg, SUM(sum_time), SUM(count_star) FROM stats_mysql_query_digest GROUP BY hostgroup;
SELECT digest,SUBSTR(digest_text,0,25),count_star,sum_time FROM stats_mysql_query_digest WHERE digest_text LIKE 'SELECT%' ORDER BY sum_time DESC LIMIT 5;
SELECT digest,SUBSTR(digest_text,0,25),count_star,sum_time FROM stats_mysql_query_digest WHERE digest_text LIKE 'SELECT%' ORDER BY count_star DESC LIMIT 5;
SELECT digest,SUBSTR(digest_text,0,255),count_star,sum_time,sum_time/count_star avg_time, min_time, max_time FROM stats_mysql_query_digest WHERE digest_text LIKE 'SELECT%' ORDER BY max_time DESC LIMIT 5;
SELECT hits, mysql_query_rules.rule_id,destination_hostgroup hg, digest,active,username, match_digest, match_pattern, replace_pattern, cache_ttl, apply FROM mysql_query_rules NATURAL JOIN stats.stats_mysql_query_rules ORDER BY mysql_query_rules.rule_id;
SELECT hostgroup,schemaname,count_star,digest,replace(replace(digest_text,'.','.'),'?','.*') QR from stats_mysql_query_digest order by count_star desc;III, Tài liệuTham khảo:
https://www.pingcap.com/blog/database-sharding-defined/
https://proxysql.com/documentation/proxysql-configuration/
https://proxysql.com/documentation/how-to-setup-proxysql-sharding/
https://proxysql.com/documentation/main-runtime/#mysql_query_rules
https://planetscale.com/blog/three-surprising-benefits-of-sharding-a-mysql-database
https://severalnines.com/resources/whitepapers/database-load-balancing-for-mysql-and-mariadb-with-proxysql/
https://severalnines.com/blog/using-sysbench-generate-test-data-sharded-table-mysql/
https://severalnines.com/wp-content/uploads/2022/05/Database_Sharding_with_MySQL_Fabric.pdf
https://www.digitalocean.com/community/tutorials/understanding-database-sharding
https://github.com/Tusamarco/blogs/blob/master/mysql_horizontal_scaling/operator_sharding_with_proxysql_public.txt