

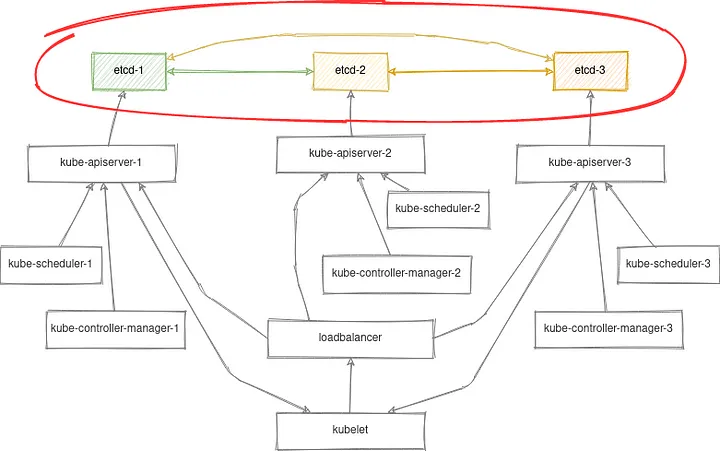
Tiếp theo bài viết về Tìm hiểu về etcd trong Kubernetes https://uptime59.com/?p=426 bài viết này sẽ hướng dẫn sao lưu cơ sở dữ liệu ETCD
Tài liệu tham khảo
https://braindose.blog/2022/02/09/etcdctl-backup-kubernetes
https://github.com/nickkeyzer/etcd-backup
https://blog.palark.com/how-to-modify-etcd-data-of-your-kubernetes-directly-without-k8s-api/
https://etcd.io/docs/v3.5/
1. Backup
Backup certificate key
Backup etcd
#!/bin/bash
while [[ "$1" != "" ]]; do
case $1 in
--etcdv3)
ETCD_VERSION=3
;;
--hourly)
ETCD_BACKUP_INTERVAL=hourly
;;
--daily)
ETCD_BACKUP_INTERVAL=daily
;;
-h | --help)
echo "Available options for etcd_backup script:"
echo -e "\n --etcdv3 Sets etcd backup version to etcdv3 API. This will not include v2 data."
echo -e "\n --hourly Sets the backup location to the hourly directory."
echo -e "\n --daily Sets the backup location to the daily directory."
echo -e "\n -h | --help Shows this help output."
exit
;;
*)
echo "invalid option specified"
exit 1
esac
shift
done
## Variables
ETCD_DATA_DIR=/var/lib/etcd #only required for etcdv3
ETCD_BACKUP_PREFIX=/mnt/nfs_read/etcd/backups/$ETCD_BACKUP_INTERVAL
ETCD_BACKUP_DIRECTORY=$ETCD_BACKUP_PREFIX/etcd-$(date +"%F")_$(date +"%T")
ENDPOINTS=https://localhost:2379
ETCDCTL_CACERT="/etc/kubernetes/pki/etcd/ca.crt"
ETCDCTL_CERT="/etc/kubernetes/pki/etcd/server.crt"
ETCDCTL_KEY="/etc/kubernetes/pki/etcd/server.key"
backup_etcdv3() {
# create the backup directory if it doesn't exist
[[ -d $ETCD_BACKUP_DIRECTORY ]] || mkdir -p $ETCD_BACKUP_DIRECTORY
cp -rp $ETCDCTL_CACERT $ETCD_BACKUP_DIRECTORY
cp -rp $ETCDCTL_CERT $ETCD_BACKUP_DIRECTORY
cp -rp $ETCDCTL_KEY $ETCD_BACKUP_DIRECTORY
# backup etcd v3 data
ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=$ENDPOINTS snapshot save $ETCD_BACKUP_DIRECTORY/snapshot.db
#--cacert $ETCDCTL_CACERT --cert $ETCDCTL_CERT --key $ETCDCTL_KEY
}
backup_logger() {
if [[ $? -ne 0 ]]; then
echo "etcdv$ETCD_VERSION $ETCD_BACKUP_INTERVAL backup failed on $HOSTNAME." | systemd-cat -t etcd_backup -p err
else
echo "etcdv$ETCD_VERSION $ETCD_BACKUP_INTERVAL backup completed successfully." | systemd-cat -t etcd_backup -p info
fi
}
# check if backup interval is set
if [[ -z "$ETCD_BACKUP_INTERVAL" ]]; then
echo "You must set a backup interval. Use either the --hourly or --daily option."
echo "See -h | --help for more information."
exit 1
fi
# run backups and log results
if [[ "$ETCD_VERSION" = "3" ]]; then
backup_etcdv3
backup_logger
# Keep last 7 etcd backups, delete the rest
cd $ETCD_BACKUP_PREFIX; ls -tp | tail -n +8 | xargs -d '\n' -r rm -r --
else
echo "You must set an etcd version. Use either the --etcdv2 or --etcdv3 option."
echo "See -h | --help for more information."
exit 1
fiTạo crontab
# Hourly etcd backups
0 * * * * sh /opt/scripts/etcd_backup.sh --etcdv3 --hourly
# Daily etcd backups
0 0 * * * sh /opt/scripts/etcd_backup.sh --etcdv3 --daily2. Restore
2.1 Thực hiện restore trên hệ thống cũ
Kiểm tra file backup
ETCDCTL_API=3 etcdctl --write-out=table snapshot status /mnt/nfs_read/etcd/backups \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.keyCác bước thực hiện khi restore
- Stop tất cả các instance của kube-api-server trên k8s cluster
- Thay thế etcd-data hiện tại bằng data từ bản backup
- Restart các service của k8s
- Kiểm tra lại kết quả thực hiện
export ETCDCTL_CACERT=/etc/kubernetes/pki/etcd/ca.crt
export ETCDCTL_CERT=/etc/kubernetes/pki/etcd/server.crt
export ETCDCTL_KEY=/etc/kubernetes/pki/etcd/server.key
export ETCDCTL_API=3
cd /mnt/nfs_read/etcd/backups/
etcdctl snapshot restore etcd_snapshot_fileTrong quá trình chạy restore nếu có lỗi có thể sử dụng thêm tham số
–skip-hash-check
NOTE: Để restore etcd thì một điều chú ý là phải stop tất cả các instance của kube-api-server, restore etcd ở tất cả các etcd instance sau đó start lại tất cả instance của kube-api-server!
Để stop hãy move tất cả các file yaml tại /etc/kubernetes/manifests/ sang thư mục backup. Chẳng hạn /opt/backup
ll /etc/kubernetes/manifests/etcd.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
mkdir /opt/backup/
mv /etc/kubernetes/manifests/*.yaml /opt/backup/
mv /var/lib/etcd/ /opt/backup/etcdutl --data-dir /var/lib/etcd snapshot restore /mnt/nfs_read/etcd/backups/snapshot.dbMove lại file /opt/backup/etcd.yaml về /etc/kubernetes/manifests/ để chạy etcd
mv /opt/backup/etcd.yaml /etc/kubernetes/manifests/ Kiểm tra dữ liệu và move các file yaml còn lại để chạy lại dịch vụ.
mv /opt/backup/*.yaml /etc/kubernetes/manifests/ 2.2 Restore Khởi tạo lại cụm cluster etcd
export ETCDCTL_CACERT=/etc/kubernetes/pki/etcd/ca.crt
export ETCDCTL_CERT=/etc/kubernetes/pki/etcd/peer.crt
export ETCDCTL_KEY=/etc/kubernetes/pki/etcd/peer.key
export ETCDCTL_API=3Move các files yaml ra khỏi /etc/kubernetes/manifests để tắt hết các pod
mkdir /opt/backup/
mv /etc/kubernetes/manifests/*.yaml /opt/backup/Restore từ file snapshot
etcdutl --data-dir /var/lib/etcd snapshot restore /opt/snapshot.db1.2 Sửa file etcd.yaml và copy lại vào /etc/kubernetes/manifests/etcd.yaml
thiết lập thông số: – –force-new-cluster để khởi tạo cụm cluster mới
mv /opt/backup/etcd.yaml /etc/kubernetes/manifests/
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://10.1.1.11:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://10.1.1.11:2380
- --force-new-cluster
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://10.1.1.11:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://10.1.1.11:2380
- --name=master01
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.k8s.io/etcd:3.5.12-0Kiểm tra tình trạng pod chạy etc với các lệnh của containerd
crictl ps -a
crictl logs -f 8eda7d6198752
etcdctl member list --write-out=table
root@master01:/var/lib/etcd# etcdctl member list --write-out=table
+------------------+---------+----------+-----------------------+------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+----------+-----------------------+------------------------+------------+
| 8e9e05c52164694d | started | master01 | http://localhost:2380 | https://10.1.1.11:2379 | false |
+------------------+---------+----------+-----------------------+------------------------+------------+
etcdctl member update 8e9e05c52164694d --peer-urls=https://10.1.1.11:2380
etcdctl endpoint health --cluster --write-out=table
root@master01:/var/lib/etcd# etcdctl endpoint health --cluster --write-out=table
+------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+------------------------+--------+-------------+-------+
| https://10.1.1.11:2379 | true | 24.234105ms | |
+------------------------+--------+-------------+-------+
Thêm member2 vào cụm cluster
Trên node1
Thêm vào theo chế độ learner chưa được phép voting lên leader
etcdctl member add --learner master02 --peer-urls=https://10.1.1.12:2380Sau khi thêm sẽ hiện tham số để cấu hình cho etcd.yaml của node2 như sau:
- --initial-advertise-peer-urls=https://10.1.1.12:2380
- --initial-cluster=master02=https://10.1.1.12:2380,master01=https://10.1.1.11:2380
- --initial-cluster-state=existingTrên node2
mkdir /opt/backup/
mv /etc/kubernetes/manifests/*.yaml /opt/backup/Xóa file member ở thư mục /var/lib/etcd
rm /var/lib/etcd/member -rf
mv /opt/backup/etcd.yaml /etc/kubernetes/manifests/Sửa file etcd.yaml và copy lại vào /etc/kubernetes/manifests/etcd.yaml
thiết lập thông số:
- --initial-advertise-peer-urls=https://10.1.1.12:2380
- --initial-cluster=master02=https://10.1.1.12:2380,master01=https://10.1.1.11:2380
- --initial-cluster-state=existingKiểm tra tình trạng của cluster trên node1:
etcdctl member list --write-out=table
etcdctl endpoint status --cluster --write-out=table
etcdctl endpoint health --cluster --write-out=tableSau khi tình trạng đã đồng bộ thực hiện promote cho phép voting thành leader
etcdctl member promote 1a497eb2ac0092f3Xóa member2 trong cụm cluster
etcdctl member remove 1a497eb2ac0092f3Làm tương tự với node3
Sau khi các node đã đồng bộ thực hiện sửa file /etc/kubernetes/manifests/etcd.yaml:
ở node1 thực hiện xóa
– –force-new-cluster
ở node2 xóa
–initial-cluster=master02=https://10.1.1.12:2380,master01=https://10.1.1.11:2380
–initial-cluster-state=existing
ở node3
–initial-cluster=master03=https://10.1.1.13:2380,master01=https://10.1.1.11:2380
–initial-cluster-state=existing
Lưu ý vẫn giữ tham số
ở node 1 – –initial-advertise-peer-urls=https://10.1.1.11:2380
ở node2 – –initial-advertise-peer-urls=https://10.1.1.12:2380
ở node 3 – –initial-advertise-peer-urls=https://10.1.1.12:2380
Như vậy là đã hoàn thành restore xong etc
Bây giở thực hiện move lại các file kube-.yaml ở /opt/backup về /etc/kubernetes/manifests mv /opt/backup/kube-.yaml /etc/kubernetes/manifests
Quá trình khởi động etc mà gặp các lỗi
osutil/interrupt_unix.go:64","msg":"received signal; shutting down","signal":"terminatedThực hiện xử lý thiết lập tham số SystemdCgroup = true rồi khởi động lại systemctl restart containerd
vim /etc/containerd/config.toml
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = trueCác lệnh xem tình trạng hệ thống
ETCDCTL_API=3 etcdctl member list --write-out=table --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key
+------------------+---------+----------+------------------------+------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+----------+------------------------+------------------------+------------+
| 58334f0709913a29 | started | master01 | https://10.1.1.11:2380 | https://10.1.1.11:2379 | false |
| 78680569136cdf45 | started | master02 | https://10.1.1.12:2380 | https://10.1.1.12:2379 | false |
| d084c1a988cd8b66 | started | master03 | https://10.1.1.13:2380 | https://10.1.1.13:2379 | false |
+------------------+---------+----------+------------------------+------------------------+------------+
ETCDCTL_API=3 etcdctl endpoint status --cluster --write-out=table --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key
Failed to get the status of endpoint https://10.1.1.13:2379 (context deadline exceeded)
+------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.1.1.11:2379 | 58334f0709913a29 | 3.5.12 | 90 MB | false | false | 66 | 1618236 | 1618236 | |
| https://10.1.1.12:2379 | 78680569136cdf45 | 3.5.12 | 90 MB | true | false | 66 | 1618236 | 1618236 | |
+------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
ETCDCTL_API=3 etcdctl endpoint health --cluster --write-out=table --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key
+------------------------+--------+-------------+---------------------------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+------------------------+--------+-------------+---------------------------+
| https://10.1.1.11:2379 | true | 18.395505ms | |
| https://10.1.1.12:2379 | true | 29.026144ms | |
| https://10.1.1.13:2379 | false | 5.00255623s | context deadline exceeded |
+------------------------+--------+-------------+---------------------------+
Error: unhealthy cluster
login over ssh on one of the master nodes and find our etcd container:
crictl ps -a --label io.kubernetes.container.name=etcd --label io.kubernetes.pod.namespace=kube-system | awk 'NR>1{r=$1} $0~/Running/{exit} END{print r}'
CONTAINER_ID=$(crictl ps -a --label io.kubernetes.container.name=etcd --label io.kubernetes.pod.namespace=kube-system | awk 'NR>1{r=$1} $0~/Running/{exit} END{print r}')
alias etcdctl='crictl exec "$CONTAINER_ID" etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt'
crictl logs "$CONTAINER_ID"
etcdctl member list -w table
ENDPOINTS=$(etcdctl member list | grep -o '[^ ]\+:2379' | paste -s -d,)
etcdctl endpoint status --endpoints=$ENDPOINTS -w tableChange leader
etcdctl move-leader id-of-the-node-you-want-to-be-the-leader3. Chỉnh sửa dữ liệu trong ETCD
Cài đặt etcdhelper
Cài đặt golang
GOPATH=/root/golang
mkdir -p $GOPATH/local
curl -sSL https://dl.google.com/go/go1.14.1.linux-amd64.tar.gz | tar -xzvC $GOPATH/local
echo "export GOPATH=\"$GOPATH\"" >> ~/.bashrc
echo 'export GOROOT="$GOPATH/local/go"' >> ~/.bashrc
echo 'export PATH="$PATH:$GOPATH/local/go/bin"' >> ~/.bashrcBuild etcdhelper tool
wget https://raw.githubusercontent.com/flant/examples/master/2020/04-etcdhelper/etcdhelper.go
go get go.etcd.io/etcd/clientv3 k8s.io/kubectl/pkg/scheme k8s.io/apimachinery/pkg/runtime
go build -o etcdhelper etcdhelper.goEdit the data in etcd
Chỉnh sửa giá trị service CIDR dùng change-service-cidr
Chỉnh sửa pod CIDR dùng change-pod-cidr
./etcdhelper -cacert /etc/kubernetes/pki/etcd/ca.crt -cert /etc/kubernetes/pki/etcd/server.crt -key /etc/kubernetes/pki/etcd/server.key -endpoint https://127.0.0.1:2379 change-service-cidr 172.24.0.0/16./etcdhelper -cacert /etc/kubernetes/pki/etcd/ca.crt -cert /etc/kubernetes/pki/etcd/server.crt -key /etc/kubernetes/pki/etcd/server.key -endpoint https://127.0.0.1:2379 change-pod-cidr 10.55.0.0/16Cài đặt etc util
https://etcd.io/docs/v3.5/install
cd /tmp && wget https://github.com/etcd-io/etcd/releases/download/v3.5.14/etcd-v3.5.14-linux-amd64.tar.gz && tar xzvf /tmp/etcd-v3.5.14-linux-amd64.tar.gz
cd /tmp/etcd*
cp -rp etcd* /usr/bin/
Check boltdb
apt install golang-go
go install go.etcd.io/bbolt/cmd/bbolt@latest
/root/go/bin/bbolt check vault.db